Google AI を利用したOCR処理 C#
AI による概要
Google AIのOCR(光学式文字認識)は、
Gemini 2.5 ProやGoogle Cloud Vision API、Document AIを活用し、画像やPDFから高精度にテキストを抽出します。手書き文字や複雑な文書も、約96%の認識率で構造化データ化でき、手軽にGoogleドライブからも利用可能です。
Google AI OCRの主要サービスと特徴
- Google Cloud Vision API: 画像内のテキストを高速・高精度に検出。手書きや多言語に対応。
- Document AI: 請求書や領収書など、構造化されたドキュメントのデータ化に特化したAI。
- Google ドライブ(ドキュメント): 画像/PDFを右クリックし、「アプリで開く」>「Googleドキュメント」で文字起こしが無料で行える。
- Gemini 2.5 Pro: AIによる文書の高度な理解・抽出が可能。
メリットと注意点
- メリット: 高い認識精度、手書き文字対応、API統合による業務自動化。
- 注意点: 認識率は100%ではなく、不鮮明な画像では誤字が発生するため、人間の確認が必要。
実行画面

画像をマウスで左上と右下を指定することで、部分的にOCR処理できます。
読込んだ画像は、[ Ocr処理 ] ボタンでテキスト化します。
[ テキスト転送 ]ボタンは、他アプリのテキストボックスへOCR結果を送ります。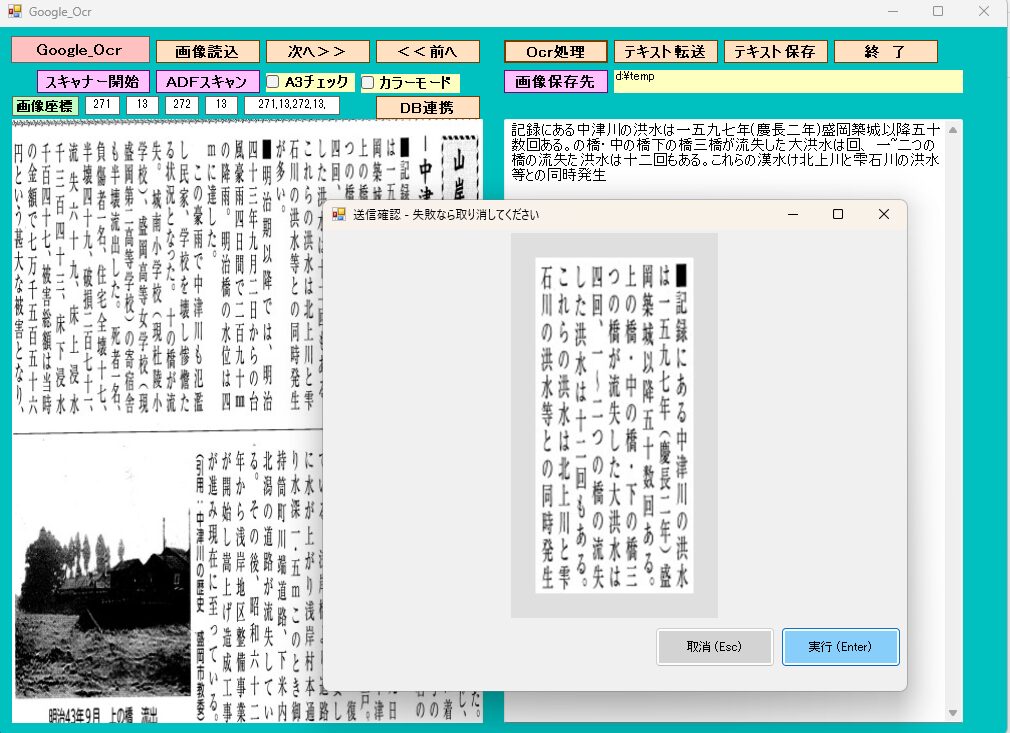
各機能の費用目安(Google Cloud API)
| 機能 | 項目 | 無料枠(月間) | 超過後の料金(目安) |
| OCR(読み取り) | Cloud Vision API | 最初の1,000ページ | 1,000ページごとに約$1.50(約230円) |
| 翻訳 | Cloud Translation API | 最初の50万文字 | 100万文字ごとに$20(約3,000円) |
| 読み上げ | Text-to-Speech API | 最初の100万〜400万文字 ※ | 100万文字ごとに$4〜$16 |
Form1

Form1.cs
using ClosedXML.Excel;
using Google.Apis.Storage.v1.Data;
using Google.Cloud.Vision.V1;
using ImageMagick;
using iTextSharp.text; // Rectangle や Document のため
using iTextSharp.text.pdf; // PdfWriter や BaseFont のため
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Data.SqlClient;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Net;
using System.Net.NetworkInformation;
using System.Runtime.InteropServices;
using System.Security.Cryptography;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using WIA;
using ZXing;
using ZXing.Windows.Compatibility;
using static Google.Cloud.Vision.V1.ImageAnnotator;
using static Google.Rpc.Context.AttributeContext.Types;
using static ScannerControl;
using static System.Windows.Forms.VisualStyles.VisualStyleElement;
using BarcodeReader = ZXing.BarcodeReader; // これも参照に追加してください
using ImageAnnotatorClient = Google.Cloud.Vision.V1.ImageAnnotatorClient;
using System.Runtime.InteropServices;
namespace FrmOcrV2
{
public partial class FrmOcrV2 : Form
{
//control clsResize
clsResize _form_resize;
[System.Runtime.InteropServices.DllImport("kernel32.dll")]
private static extern bool AllocConsole();
private ImageAnnotatorClient client;
private string outdir = "";
private MagickImageCollection pdfImages; // PDFの各ページを保持する箱
int currentPage = 0; // 現在表示中のページ番号
private Google.Cloud.Vision.V1.Image imageForVision;
// クラスの上のほうで宣言
private List<string> actualFilePaths = new List<string>(); // スキャンした全パスを保存
private string actualFilePath = ""; // 今表示している1枚のパス
private string currentPdfPath = ""; // 現在表示中のPDF
//マウスポイント用
ImageMagick.MagickImage originalMagickImage;
System.Drawing.Point startPoint;
System.Drawing.Point endPoint;
bool isFirstClick = true;
private string selectedOcrFolder = ""; // 選択されたフォルダパスを保持
// 1. データを渡すためのイベントを定義
public event Action<string> TextConfirmed;
public FrmOcrV2()
{
InitializeComponent();
_form_resize = new clsResize(this); //I put this after the initialize event to be sure that all controls are initialized properly
this.Load += new EventHandler(_Load); //This will be called after the initialization // form_load
this.Resize += new EventHandler(_Resize); //form_resize
//AllocConsole();
// プロセス環境変数の設定
string secretPath = Application.StartupPath + "\\sxxxxxx-xxx-xxxxxxx-xx-xxxxxxxxxxxxx.json";
System.Environment.SetEnvironmentVariable("GOOGLE_APPLICATION_CREDENTIALS", secretPath, EnvironmentVariableTarget.Process);
client = ImageAnnotatorClient.Create();
//既定出力フォルダ
/*
try
{
StreamReader sr3 = new StreamReader(Application.StartupPath + "\\teisu.txt", Encoding.GetEncoding("UTF-8"));
while (sr3.Peek() != -1)
{
outdir = sr3.ReadLine();
}
sr3.Close();
}
catch
{
outdir = @"d:\temp";
}
*/
string filePath = System.IO.Directory.GetCurrentDirectory() + @"\teisu.txt";
if (File.Exists(filePath))
{
// 全行を読み込む
string[] lines = File.ReadAllLines(filePath);
outdir = lines[0];
}
else
{
MessageBox.Show("設定ファイルが存在しません。処理>設定をしてください", "エラー");
}
lblFolderPath.Text = outdir;
selectedOcrFolder = outdir;
pictureBox1.AllowDrop = true;
}
//clsResize _Load
private void _Load(object sender, EventArgs e)
{
_form_resize._get_initial_size();
}
//clsResize _Resize
private void _Resize(object sender, EventArgs e)
{
_form_resize._resize();
}
//「マウスがコントロールの上に来たとき、受け入れ可能か」を判定します。
private void pictureBox1_DragEnter(object sender, DragEventArgs e)
{
// ファイル形式であれば、マウスカーソルを「コピー」の形にする
// マウスがファイルを引き連れてきたかチェック
if (e.Data.GetDataPresent(DataFormats.FileDrop))
{
e.Effect = DragDropEffects.Copy; // カーソルを「+」にする
}
}
//「指を離したとき、実際にファイルを受け取って処理」をします。
private void pictureBox1_DragDrop(object sender, DragEventArgs e)
{
string[] files = (string[])e.Data.GetData(DataFormats.FileDrop);
if (files.Length <= 0) return;
string filePath = files[0];
string extension = System.IO.Path.GetExtension(filePath).ToLower();
// 前のデータをクリア
pdfImages?.Dispose();
pdfImages = new MagickImageCollection();
if (extension == ".pdf")
{
// PDFの場合:全ページ読み込み
var settings = new MagickReadSettings { Density = new Density(300) };
pdfImages.Read(filePath, settings);
}
else if (extension == ".jpg" || extension == ".jpeg" || extension == ".png")
{
// 画像の場合:その1枚だけをコレクションに追加
pdfImages.Read(filePath);
}
currentPage = 0; // 1枚目(0番目)にセット
DisplayCurrentPage(); // 画面に表示
}
// PDFを画像化して表示するメソッド
private void LoadPdfToPictureBox(string pdfPath)
{
var settings = new MagickReadSettings();
settings.Density = new Density(600); // 高解像度で読み込む
using (var images = new MagickImageCollection())
{
images.Read(pdfPath, settings);
// 最初の1ページ目を表示用にメモリに書き出す
using (var memStream = new MemoryStream())
{
images[0].Write(memStream, MagickFormat.Png);
pictureBox1.Image?.Dispose();
pictureBox1.Image = System.Drawing.Image.FromStream(memStream);
// ここでこの memStream.ToArray() を使って
// Google Vision API へ飛ばせばOKです!
}
}
}
//Ocr処理
private async void StartOcr(string filepass)
{
try
{
//ロード時に初期化
//var client = ImageAnnotatorClient.Create();
Google.Cloud.Vision.V1.Image imageForVision = null;
// --- PDFの場合の処理 ---
if (Path.GetExtension(filepass).ToLower() == ".pdf")
{
using (var images = new ImageMagick.MagickImageCollection())
{
// 読み込み設定 (DPIを上げると精度が上がります)
var settings = new ImageMagick.MagickReadSettings { Density = new ImageMagick.Density(300) };
// PDFの1ページ目だけを読み込む (ファイルパスの末尾に [0] をつけるのがコツ)
images.Read(filepass + "[0]", settings);
using (var memStream = new MemoryStream())
{
// Magick.NETで画像をストリームに書き出す
images[0].Write(memStream, ImageMagick.MagickFormat.Png);
// バイト配列を取得
byte[] imageBytes = memStream.ToArray();
// --- Vision API への受け渡し ---
imageForVision = Google.Cloud.Vision.V1.Image.FromBytes(imageBytes);
// --- PictureBox への表示処理 ---
// 一度メモリをリセットして読み込む
using (var displayStream = new MemoryStream(imageBytes))
{
// 以前の画像をクリアしてメモリを解放(必要に応じて)
pictureBox1.Image?.Dispose();
// ストリームから画像を生成してセット
pictureBox1.Image = System.Drawing.Image.FromStream(displayStream);
}
}
}
}
// --- 通常の画像の場合 ---
else
{
imageForVision = Google.Cloud.Vision.V1.Image.FromFile(filepass);
using (var fs = new System.IO.FileStream(filepass, System.IO.FileMode.Open, System.IO.FileAccess.Read))
{
pictureBox1.Image = System.Drawing.Image.FromStream(fs);
}
}
// OCR実行
var response = await client.DetectTextAsync(imageForVision);
if (response.Count > 0)
{
textBox1.Text = response[0].Description;
textBox1.Text = textBox1.Text.Replace("。", "。\r\n");//.Trim(); // 確認用
// 自動整形
//
}
}
catch (Exception ex)
{
// ここでエラーの詳細(Ghostscriptが必要など)が表示されるはずです
MessageBox.Show("OCRエラー: " + ex.Message + "\n" + ex.InnerException?.Message);
}
}
//画像選択
private async void button11_Click(object sender, EventArgs e)
{
using (OpenFileDialog ofd = new OpenFileDialog())
{
ofd.Filter = "画像・PDF|*.jpg;*.png;*.bmp;*.pdf";
if (ofd.ShowDialog() != DialogResult.OK) return;
try
{
//ロード時に初期化
//var client = ImageAnnotatorClient.Create();
Google.Cloud.Vision.V1.Image imageForVision = null;
// --- PDFの場合の処理 ---
if (Path.GetExtension(ofd.FileName).ToLower() == ".pdf")
{
// PDFの全ページを一括読み込み
pdfImages?.Dispose(); // 前のデータがあれば消す
var settings = new MagickReadSettings { Density = new Density(600) };//300--->600
pdfImages = new MagickImageCollection();
pdfImages.Read(ofd.FileName, settings);
currentPage = 0; // 1ページ目にリセット
DisplayCurrentPage(); // 画面に表示
}
// --- 通常の画像の場合 ---
else
{
// 前のデータをクリア
pdfImages?.Dispose();
pdfImages = new MagickImageCollection();
// 画像の場合:その1枚だけをコレクションに追加
pdfImages.Read(ofd.FileName);
actualFilePath = ofd.FileName;
currentPage = 0; // 1枚目(0番目)にセット
DisplayCurrentPage(); // 画面に表示
}
}
catch (Exception ex)
{
// ここでエラーの詳細(Ghostscriptが必要など)が表示されるはずです
MessageBox.Show("選択エラー: " + ex.Message + "\n" + ex.InnerException?.Message);
}
}
}
// 現在のページを表示する共通メソッド
private void DisplayCurrentPage()
{
if (pdfImages == null || pdfImages.Count == 0) return;
// 現在のページを取得
var currentMagickImage = pdfImages[currentPage];
// --- 【重要】ここが「BMP品質」のキモです ---
// 透過(アルファチャンネル)を消し、背景を完全に白で塗りつぶす
currentMagickImage.Alpha(ImageMagick.AlphaOption.Remove);
currentMagickImage.BackgroundColor = ImageMagick.MagickColors.White;
// 画像の品質を劣化させない設定
currentMagickImage.ColorType = ImageMagick.ColorType.TrueColor;
// ------------------------------------------
// OCR解析用の変数にクローンを保存
if (originalMagickImage != null) originalMagickImage.Dispose();
originalMagickImage = (ImageMagick.MagickImage)currentMagickImage.Clone();
using (MemoryStream ms = new MemoryStream())
{
// ここをBmpにすることで、ピクセル情報をそのままPictureBoxに渡します
currentMagickImage.Write(ms, ImageMagick.MagickFormat.Bmp);
ms.Position = 0;
if (pictureBox1.Image != null) pictureBox1.Image.Dispose();
pictureBox1.Image = System.Drawing.Image.FromStream(ms);
}
}
// 「次へ」ボタン(デザイン画面で作成してクリックイベントを追加)
private void btnNext_Click(object sender, EventArgs e)
{
if (actualFilePaths != null && currentPage < actualFilePaths.Count - 1)
{
currentPage++;
// 1. 今のページのパスを更新
actualFilePath = actualFilePaths[currentPage];
// 2. 画面表示の更新(既存のメソッドを呼ぶ)
DisplayCurrentPage();
// 3. MagickImageも現在のパスで更新
if (originalMagickImage != null) originalMagickImage.Dispose();
originalMagickImage = new ImageMagick.MagickImage(actualFilePath);
}
}
// 「前へ」ボタン
private void btnPrev_Click(object sender, EventArgs e)
{
if (actualFilePaths != null && currentPage > 0)
{
currentPage--;
// 1. 今のページのパスを更新
actualFilePath = actualFilePaths[currentPage];
// 2. 画面表示の更新
DisplayCurrentPage();
// 3. MagickImageも更新
if (originalMagickImage != null) originalMagickImage.Dispose();
originalMagickImage = new ImageMagick.MagickImage(actualFilePath);
}
}
//Ocr処理
private async void btnRunOcr_Click(object sender, EventArgs e)
{
if (pictureBox1.Image == null) return;
textBox1.Text = "";
// 現在表示されている「最新のパス」を使って呼び出すだけ!
if (!string.IsNullOrEmpty(actualFilePath))
{
byte[] imageBytes = File.ReadAllBytes(actualFilePath);
await strRunOcr(imageBytes, actualFilePath, true); // PDF作成フラグをtrueに
}
}
//最初のQRコードだけを読み取る
private string ScanQrCode(Bitmap bitmap)
{
try
{
// QRコードリーダーの準備
var reader = new BarcodeReader();
// 画像からQRコードを探して解析
var result = reader.Decode(bitmap);
if (result != null)
{
// 見つかったら、その中身(URLなど)を返す
return result.Text;
}
}
catch
{
// 読み取り失敗時はスルー
}
return null;
}
//すべてのQRコードを読み取る
private List<string> ScanAllQrCodes(Bitmap bitmap)
{
var qrResults = new List<string>();
try
{
var reader = new BarcodeReader();
// --- 解析精度を上げるための設定を追加 ---
reader.Options = new ZXing.Common.DecodingOptions
{
TryHarder = true, // 時間をかけてより深く解析する
PossibleFormats = new List<BarcodeFormat> { BarcodeFormat.QR_CODE }, // QRコードに限定して精度を上げる
// 純粋な白黒として扱う設定を追加
PureBarcode = false // 反転した色(白黒逆転)も探さない。true=探す。
};
// 【重要】画像をグレースケールに変換して読み取り精度を上げる
using (Bitmap grayBitmap = MakeGrayscale(bitmap))
{
var results = reader.DecodeMultiple(grayBitmap); //マルチ
if (results != null)
{
foreach (var result in results)
{
qrResults.Add(result.Text);
}
}
}
}
catch { /* エラー処理 */ }
return qrResults;
}
// 画像を白黒にする補助メソッド
private Bitmap MakeGrayscale(Bitmap original)
{
Bitmap newBitmap = new Bitmap(original.Width, original.Height);
using (Graphics g = Graphics.FromImage(newBitmap))
{
var colorMatrix = new System.Drawing.Imaging.ColorMatrix(
new float[][] {
new float[] {.3f, .3f, .3f, 0, 0},
new float[] {.59f, .59f, .59f, 0, 0},
new float[] {.11f, .11f, .11f, 0, 0},
new float[] {0, 0, 0, 1, 0},
new float[] {0, 0, 0, 0, 1}
});
var attributes = new System.Drawing.Imaging.ImageAttributes();
attributes.SetColorMatrix(colorMatrix);
g.DrawImage(original, new System.Drawing.Rectangle(0, 0, original.Width, original.Height),
0, 0, original.Width, original.Height, GraphicsUnit.Pixel, attributes);
}
return newBitmap;
}
//画像クリック
private async void pictureBox1_Click(object sender, EventArgs e)
{
var mouseEventArgs = (MouseEventArgs)e;
if (isFirstClick)
{
startPoint = mouseEventArgs.Location;
isFirstClick = false;
// 確認用に小さな印を出すなどの処理をしても良いです
}
else
{
endPoint = mouseEventArgs.Location;
isFirstClick = true; // 次のためにリセット
// ここで OCR 実行
await RunRangeOcr();
}
}
private void pictureBox1_MouseClick(object sender, MouseEventArgs e)
{
try
{
System.Drawing.Image img = pictureBox1.Image;
Point pos = new Point(0, 0);
pos.X = e.Location.X * img.Width / pictureBox1.Width;
pos.Y = e.Location.Y * img.Height / pictureBox1.Height;
textBox6.Text += textBox6.Text + pos.X + "," + pos.Y + ",";
string[] xy = textBox6.Text.Split(',');
if (xy.Length > 4)
{
textBox2.Text = xy[xy.Length - 5];
textBox3.Text = xy[xy.Length - 4];
textBox4.Text = xy[xy.Length - 3];
textBox5.Text = xy[xy.Length - 2];
textBox6.Text = xy[xy.Length - 5] + ",";
textBox6.Text += xy[xy.Length - 4] + ",";
textBox6.Text += xy[xy.Length - 3] + ",";
textBox6.Text += xy[xy.Length - 2] + ",";
}
}
catch (Exception)
{
;
}
}
//部分読み取り
private async Task RunRangeOcr()
{
if (originalMagickImage == null) return;
// 1. 座標の整理
int x = Math.Min(startPoint.X, endPoint.X);
int y = Math.Min(startPoint.Y, endPoint.Y);
int width = Math.Abs(startPoint.X - endPoint.X);
int height = Math.Abs(startPoint.Y - endPoint.Y);
// ガード:小さすぎる範囲は無視
if (width < 5 || height < 5) return;
// 2. 比率計算(ストレッチモード)
double ratioX = (double)originalMagickImage.Width / (double)pictureBox1.Width;
double ratioY = (double)originalMagickImage.Height / (double)pictureBox1.Height;
int realX = (int)(x * ratioX);
int realY = (int)(y * ratioY);
int realW = (int)(width * ratioX);
int realH = (int)(height * ratioY);
// 3. Magick.NET で切り抜き
using (ImageMagick.MagickImage cropImage = (ImageMagick.MagickImage)originalMagickImage.Clone())
{
// 1. 指定範囲で切り抜き
cropImage.Crop(new ImageMagick.MagickGeometry(realX, realY, (uint)realW, (uint)realH));
cropImage.Page = new ImageMagick.MagickGeometry(0, 0, 0, 0);
// 2. ★加工を捨てて「拡大」に全振りする
// 漢字と英字の「線」を太らせず、解像度だけを2倍に上げます
cropImage.Resize(new ImageMagick.MagickGeometry(cropImage.Width * 2, 0));
cropImage.Alpha(ImageMagick.AlphaOption.Remove);
cropImage.BackgroundColor = ImageMagick.MagickColors.White;
cropImage.Border(40); // 余白をさらに広くしてAIの視界を広げる
byte[] croppedBytes = cropImage.ToByteArray(ImageMagick.MagickFormat.Png);
// ★ 3. ポップアップ表示
ShowPreview(croppedBytes, actualFilePath);
// 4. Google Vision API 呼び出し
//await strRunOcr(croppedBytes);
}
}
/*
💡 今後のための「最強のOCR設定」まとめ
「PNG」は絶対: JPGのノイズはAIの大敵。
「Resize」で2倍に: 細い文字(特に英字の i や l)は、物理的に太らせるより「解像度を2倍にする」方が、文字化けせず綺麗に読める。
「Border(余白)」は命: 画像の端に文字があるとGoogle AIは無視する。「Border(40)」程度で文字を中央に浮かせるのがベスト。
「TextDetection」を優先: 文末が削られるときは、段落解析(Document)よりも、単一文字認識(Text)の結果を採用する。
*/
// --- 以下、プレビュー用のメソッド ---
private async void ShowPreview(byte[] imageBytes, string actualFilePath)
{
using (var ms = new MemoryStream(imageBytes))
{
using (Form popup = new Form())
{
popup.Text = "送信確認 - 失敗なら取り消してください";
popup.Size = new Size(600, 500);
popup.StartPosition = FormStartPosition.CenterScreen;
popup.TopMost = true;
// レイアウト(上:画像、下:ボタンエリア)
TableLayoutPanel layout = new TableLayoutPanel { Dock = DockStyle.Fill, RowCount = 2 };
layout.RowStyles.Add(new RowStyle(SizeType.Percent, 85F));
layout.RowStyles.Add(new RowStyle(SizeType.Percent, 15F));
// 画像表示
PictureBox pb = new PictureBox { Image = System.Drawing.Image.FromStream(ms), Dock = DockStyle.Fill, SizeMode = PictureBoxSizeMode.Zoom };
// ボタンエリア(横に並べる)
FlowLayoutPanel buttonPanel = new FlowLayoutPanel { Dock = DockStyle.Fill, FlowDirection = FlowDirection.RightToLeft };
// 取消ボタン
System.Windows.Forms.Button btnCancel = new System.Windows.Forms.Button { Text = "取消 (Esc)", Width = 120, Height = 40, BackColor = Color.LightGray };
btnCancel.Click += (s, e) => { popup.DialogResult = DialogResult.Cancel; popup.Close(); };
// 実行ボタン
System.Windows.Forms.Button btnOk = new System.Windows.Forms.Button { Text = "実行 (Enter)", Width = 120, Height = 40, BackColor = Color.LightSkyBlue };
btnOk.Click += (s, e) => { popup.DialogResult = DialogResult.OK; popup.Close(); };
buttonPanel.Controls.Add(btnOk);
buttonPanel.Controls.Add(btnCancel);
layout.Controls.Add(pb, 0, 0);
layout.Controls.Add(buttonPanel, 0, 1);
popup.Controls.Add(layout);
// キー入力対応
popup.AcceptButton = btnOk; // Enterで実行
popup.CancelButton = btnCancel; // Escで取消
// ダイアログを表示し、結果が OK の時だけ OCR を実行する
if (popup.ShowDialog() == DialogResult.OK)
{
await strRunOcr(imageBytes, actualFilePath, false);
//string path = Path.Combine(outdir, "OCR_History.xlsx");
//SaveToExcel(textBox1.Text,path);
}
else
{
// 取消された場合は何もしない(またはメッセージを出す)
textBox1.Text = "キャンセルされました。";
}
}
}
}
//ocr処理
private async Task strRunOcr(byte[] imageBytes, string actualFilePath, bool createPdf)
{
if (imageBytes == null) return;
textBox1.Clear();
// 1. 画像データの準備
var imageV = Google.Cloud.Vision.V1.Image.FromBytes(imageBytes);
// 2. ★奥の手1:二重のFeature(書類解析 + 単純文字検出)
// これにより、引用部分などの「薄い・細かい」文字の読み飛ばしを防ぎます
var featDocument = new Google.Cloud.Vision.V1.Feature { Type = Google.Cloud.Vision.V1.Feature.Types.Type.DocumentTextDetection };
var featText = new Google.Cloud.Vision.V1.Feature { Type = Google.Cloud.Vision.V1.Feature.Types.Type.TextDetection };
// 3. ★奥の手2:言語ヒントの明示
// 「これは日本語と英語だ」と教えることで、漢字の構成(へん・つくり)の推論精度を上げます
var imageContext = new Google.Cloud.Vision.V1.ImageContext
{
LanguageHints = { "ja", "en" }
};
// 4. リクエスト作成
var req = new Google.Cloud.Vision.V1.AnnotateImageRequest
{
Image = imageV,
ImageContext = imageContext
};
req.Features.Add(featDocument);
req.Features.Add(featText);
// 5. 実行
var resList = await client.BatchAnnotateImagesAsync(new[] { req });
var res = resList.Responses[0];
if (createPdf == true)
{
// 5-2. 座標情報をリスト化する
List<OcrWordInfo> words = GetWordCoordinates(res.FullTextAnnotation);
// 5-3. iTextSharp を使って透明テキスト付きPDFを作成
string pdfPath = Path.ChangeExtension(actualFilePath, ".pdf");
CreateSearchablePdf(actualFilePath, pdfPath, words);
currentPdfPath = pdfPath;
MessageBox.Show("検索可能なPDFを作成しました!");
}
// 6. 結果の解析(ループ処理は以前のままでOKですが、結果をマージします)
if (res.TextAnnotations.Count > 0)
{
// TextAnnotations[0] には、AIが「見たまま」を繋げた全テキストが入っています
string rawText = res.TextAnnotations[0].Description;
// もし周囲の文字を含めた範囲でも、ここなら「差出人」が漏れなく入っているはずです
textBox1.Text += rawText;
}
else if (res.FullTextAnnotation != null)
{
// 基本は FullTextAnnotation (Documentモードの結果) を使う
if (res.FullTextAnnotation != null)
{
System.Text.StringBuilder sb = new System.Text.StringBuilder();
foreach (var page in res.FullTextAnnotation.Pages)
{
foreach (var block in page.Blocks)
{
foreach (var para in block.Paragraphs)
{
string line = "";
foreach (var word in para.Words)
{
foreach (var symbol in word.Symbols)
{
line += symbol.Text;
if (symbol.Property != null && symbol.Property.DetectedBreak != null)
{
string typeStr = symbol.Property.DetectedBreak.Type.ToString();
// 文中のスペースのみ処理。改行はsb.AppendLineに任せる
if (typeStr.Contains("Space"))
{
line += " ";
}
else if (typeStr.Contains("LineFeed") || typeStr.Contains("EolAfter"))
{
// 行末に来たら結合(Azureのように自然な流れにする)
// もし強制改行したい場合はここに line += Environment.NewLine;
}
}
}
}
sb.AppendLine(line); // 段落単位で改行
}
}
}
textBox1.Text += sb.ToString();
}
// もし Documentモードで何も取れなかった時のためのバックアップ
else if (res.TextAnnotations.Count > 0)
{
textBox1.Text = res.TextAnnotations[0].Description;
}
}
//名称付画像保存
if (createPdf == true)
{
MessageBox.Show("autosave");
// 画像の自動保存(OCR後の名前でリネームする場合など)
// ここも actualFilePath(元のファイル)を渡すように調整が必要です
AutoSaveScannedImage(actualFilePath, textBox1.Text);
}
// --- QRコードの読み取りを追加 ---
// バイト配列から一時的にBitmapを作成してQRスキャンに回す
using (MemoryStream qrms = new MemoryStream(imageBytes))
using (Bitmap qrBmp = new Bitmap(qrms))
{
List<string> qrList = ScanAllQrCodes(qrBmp);
if (qrList != null && qrList.Count > 0)
{
textBox1.AppendText("【QRリンク一覧】" + Environment.NewLine);
foreach (string url in qrList)
{
textBox1.AppendText("・ " + url + Environment.NewLine);
}
textBox1.AppendText("----------------" + Environment.NewLine);
}
}
//Excel履歴保存
if (createPdf == true)
{
MessageBox.Show("savetoexcel");
// 6. Excel保存
string path = Path.Combine(outdir, "OCR_History.xlsx"); //outdir + @"\\OCR_History.xlsx";
try
{
// 通常の保存処理
SaveToExcel(textBox1.Text, path);
}
catch (IOException)
{
// 使用中の場合は別名で保存
string altPath = Path.Combine(outdir, $"OCR_History_{DateTime.Now:HHmmss}.xlsx"); // outdir + $"\\OCR_History_{DateTime.Now:HHmmss}.xlsx";
SaveToExcel(textBox1.Text, altPath);
// ユーザーに通知(任意)
this.Text = "Excel使用中のため別名で保存しました";
}
}
}
//画像変換後、Ocr処理実行
/*
private async Task RunFullPageOcr()
{
if (originalMagickImage == null) return;
using (var processImage = (ImageMagick.MagickImage)originalMagickImage.Clone())
{
// 1. 背景を白くし、透過を削除(認識率向上のため)
processImage.Alpha(ImageMagick.AlphaOption.Remove);
processImage.BackgroundColor = ImageMagick.MagickColors.White;
// 2. 高品質JPGに変換する設定(ここが重要)
// 品質(Quality)を 95~100 にすれば、OCR精度はBMPと変わりません
processImage.Quality = 95;
// 3. BMPではなく Jpeg 形式でバイト配列を作成
// これによりサイズが劇的に小さくなり、10MB制限を回避できます
byte[] imageBytes = processImage.ToByteArray(ImageMagick.MagickFormat.Jpeg);
// 4. サイズチェック(念のため)
if (imageBytes.Length > 10 * 1024 * 1024)
{
// まだ大きい場合は少し解像度を下げるか、Qualityを落とす
processImage.Resize(new ImageMagick.MagickGeometry("2000x2000>"));
imageBytes = processImage.ToByteArray(ImageMagick.MagickFormat.Jpeg);
}
await strRunOcrDirect(imageBytes, lastScannedFilePath, true);
}
}
//ocrの処理
private async Task strRunOcrDirect(byte[] imageBytes,string lastScannedFilePath, bool createPdf)
{
if (imageBytes == null) return;
textBox1.Clear();
// --- 1. QRコードの読み取りを追加 ---
// バイト配列から一時的にBitmapを作成してQRスキャンに回す
using (MemoryStream qrms = new MemoryStream(imageBytes))
using (Bitmap qrBmp = new Bitmap(qrms))
{
List<string> qrList = ScanAllQrCodes(qrBmp);
if (qrList != null && qrList.Count > 0)
{
textBox1.AppendText("【QRリンク一覧】" + Environment.NewLine);
foreach (string url in qrList)
{
textBox1.AppendText("・ " + url + Environment.NewLine);
}
textBox1.AppendText("----------------" + Environment.NewLine);
}
}
// --- 2. Google Vision API への画像データ準備 ---
var imageV = Google.Cloud.Vision.V1.Image.FromBytes(imageBytes);
var feat = new Google.Cloud.Vision.V1.Feature
{
Type = Google.Cloud.Vision.V1.Feature.Types.Type.DocumentTextDetection
};
var req = new Google.Cloud.Vision.V1.AnnotateImageRequest { Image = imageV };
req.Features.Add(feat);
// 3. 実行
var resList = await client.BatchAnnotateImagesAsync(new[] { req });
// 4. 結果の解析と表示
if (resList.Responses.Count > 0 && resList.Responses[0].FullTextAnnotation != null)
{
var res = resList.Responses[0];
// 4-2. 座標情報をリスト化する
List<OcrWordInfo> words = GetWordCoordinates(resList.Responses[0].FullTextAnnotation);
// 4-3. iTextSharp を使って透明テキスト付きPDFを作成
string pdfPath = Path.ChangeExtension(lastScannedFilePath, ".pdf");
CreateSearchablePdf(lastScannedFilePath, pdfPath, words);
MessageBox.Show("検索可能なPDFを作成しました!");
System.Text.StringBuilder sb = new System.Text.StringBuilder();
foreach (var page in res.FullTextAnnotation.Pages)
{
foreach (var block in page.Blocks)
{
foreach (var para in block.Paragraphs)
{
string line = "";
foreach (var word in para.Words)
{
foreach (var symbol in word.Symbols)
{
line += symbol.Text;
if (symbol.Property != null && symbol.Property.DetectedBreak != null)
{
string typeStr = symbol.Property.DetectedBreak.Type.ToString();
// 文中のスペースのみ処理。改行はsb.AppendLineに任せる
if (typeStr.Contains("Space"))
{
line += " ";
}
else if (typeStr.Contains("LineFeed") || typeStr.Contains("EolAfter"))
{
// 行末に来たら結合(Azureのように自然な流れにする)
// もし強制改行したい場合はここに line += Environment.NewLine;
}
}
}
}
sb.AppendLine(line);
}
}
}
// QRコードの結果の後ろにOCRテキストを追加
textBox1.AppendText(sb.ToString());
}
}
*/
// --- OCR実行後の保存処理 ---
private void SaveToExcel(string recognizedText, string filePath)
{
//string filePath = outdir + @"\\OCR_History.xlsx";
XLWorkbook workbook;
IXLWorksheet worksheet;
// 1. ファイルが存在するか確認
if (!File.Exists(filePath))
{
// 新規作成
workbook = new XLWorkbook();
worksheet = workbook.Worksheets.Add("履歴");
// 見出し作成
worksheet.Cell(1, 1).Value = "日付";
worksheet.Cell(1, 2).Value = "時刻";
worksheet.Cell(1, 3).Value = "認識結果(履歴)";
// 見出しを少し太字にする
worksheet.Range("A1:C1").Style.Font.Bold = true;
worksheet.Range("A1:C1").Style.Fill.BackgroundColor = XLColor.LightGray;
}
else
{
// 既存ファイルを開く
workbook = new XLWorkbook(filePath);
worksheet = workbook.Worksheet(1);
}
// 2. データの最終行を見つけて、次の行に追記
int nextRow = worksheet.LastRowUsed()?.RowNumber() + 1 ?? 2;
DateTime now = DateTime.Now;
worksheet.Cell(nextRow, 1).Value = now.ToString("yyyy/MM/dd"); // 日付
worksheet.Cell(nextRow, 2).Value = now.ToString("HH:mm:ss"); // 時刻
worksheet.Cell(nextRow, 3).Value = recognizedText; // 履歴
// 列幅を自動調整
worksheet.Columns().AdjustToContents();
// 3. 保存して閉じる
workbook.SaveAs(filePath);
}
//終了
private void button3_Click(object sender, EventArgs e)
{
this.Close();
}
// 保存用共通メソッド
private void SaveTextToFile(string content, string defaultName)
{
if (string.IsNullOrWhiteSpace(content))
{
MessageBox.Show("保存する内容がありません。");
return;
}
using (SaveFileDialog saveFileDialog = new SaveFileDialog())
{
saveFileDialog.InitialDirectory = outdir + "\\"; //System.Environment.CurrentDirectory + @"\";
saveFileDialog.FileName = defaultName;
saveFileDialog.Filter = "テキストファイル (*.txt)|*.txt";
if (saveFileDialog.ShowDialog() == DialogResult.OK)
{
System.IO.File.WriteAllText(saveFileDialog.FileName, content);
MessageBox.Show("保存が完了しました。");
}
}
}
//テキスト保存
private void button2_Click(object sender, EventArgs e)
{
//日付時刻取得
DateTime nowTime;
string str_nowTime;
nowTime = DateTime.Now;
str_nowTime = nowTime.ToString("yyyyMMdd_HHmmss");
SaveTextToFile(textBox1.Text, "OCRテキスト_" + str_nowTime + ".txt");
}
// Windowsの通信用のおまじない(構造体)
[StructLayout(LayoutKind.Sequential)]
public struct COPYDATASTRUCT
{
public IntPtr dwData;
public int cbData;
public IntPtr lpData;
}
//テキスト転送
private void button1_Click(object sender, EventArgs e)
{
// 送り先(Documentソフト)のウィンドウタイトルを探す
IntPtr hWnd = FindWindow(null, "Google_Doc"); // "Documentソフトのウィンドウ名"ここを正確に!
if (hWnd != IntPtr.Zero)
{
byte[] sarr = System.Text.Encoding.Default.GetBytes(textBox1.Text);
int len = sarr.Length;
COPYDATASTRUCT cds;
cds.dwData = (IntPtr)100;
cds.lpData = Marshal.AllocCoTaskMem(len);
Marshal.Copy(sarr, 0, cds.lpData, len);
cds.cbData = len;
// メッセージを送信(WM_COPYDATA = 0x004A)
SendMessage(hWnd, 0x004A, this.Handle, ref cds);
Marshal.FreeCoTaskMem(cds.lpData);
}
//this.Close();
}
[DllImport("User32.dll")]
public static extern IntPtr FindWindow(string lpClassName, string lpWindowName);
[DllImport("User32.dll")]
public static extern int SendMessage(IntPtr hWnd, int Msg, IntPtr wParam, ref COPYDATASTRUCT lParam);
//スキャナー開始
private async void button4_Click(object sender, EventArgs e)
{
ScannerControl scanner = new ScannerControl();
// 保存先フォルダ
string saveDir = string.IsNullOrEmpty(selectedOcrFolder)
? Path.Combine(Application.StartupPath, "ScannedDocs")
: selectedOcrFolder;
try
{
// 1. スキャン実行(useADFはfalse=単票。ADFボタンならここをtrueにする)
// StartScanは保存されたファイルのフルパスをリストで返します
// 引数の最後にカラーモード(カラーなら1、白黒なら4)を渡します
int mode = chkColor.Checked ? 1 : 4;
List<string> filePaths = scanner.StartScan(saveDir, false, chkA3Mode.Checked, mode);
if (filePaths != null && filePaths.Count > 0)
{
// 2. 【重要】リストの最初にある「実際のファイルパス」を取り出す// スキャン直後にセット
actualFilePaths = filePaths; // ★ここでパスを「保存用リスト」に記憶させる
actualFilePath = filePaths[0];
currentPage = 0;
// --- 以前のデータをクリア ---
pdfImages?.Dispose();
pdfImages = new MagickImageCollection();
// 3. フォルダ(saveDir)ではなく、ファイル(actualFilePath)を読み込む
// これで「アクセス拒否」が直ります
byte[] imageBytes = File.ReadAllBytes(actualFilePath);
pdfImages.Read(imageBytes);
currentPage = 0;
DisplayCurrentPage();
// 4. OCR実行(画像データを渡す)
await strRunOcr(imageBytes, actualFilePath, true);
// 5. Excel保存
//SaveToExcel(textBox1.Text);
// 6. 画像の自動保存(OCR後の名前でリネームする場合など)
// ここも actualFilePath(元のファイル)を渡すように調整が必要です
//AutoSaveScannedImage(actualFilePath, textBox1.Text);
MessageBox.Show("処理が完了しました。");
}
}
catch (Exception ex)
{
// ここでエラーが出た場合、ex.Messageに詳細が出ます
MessageBox.Show(ex.Message, "エラー", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
//名前自動保存
private string GenerateSafeFileName(string ocrText)
{
// 1. 日付を取得 (例: 20260124_1030)
string timestamp = DateTime.Now.ToString("yyyyMMdd_HHmm");
// 2. OCR結果から最初の1行(または20文字)を抽出
string keyword = "ScanDocument"; // デフォルト
if (!string.IsNullOrWhiteSpace(ocrText))
{
// 改行があれば最初の1行目だけ取る
string firstLine = ocrText.Split(new[] { '\n', '\r' }, StringSplitOptions.RemoveEmptyEntries)[0];
// 長すぎる場合はカットし、ファイル名禁止文字を除去
keyword = string.Join("_", firstLine.Split(Path.GetInvalidFileNameChars())).Trim();
if (keyword.Length > 20) keyword = keyword.Substring(0, 20);
}
// 3. 組み合わせる (例: 20260124_1030_令和8年_町内会_新年会.jpg)
return $"{timestamp}_{keyword}.jpg";
}
// OCR処理後の実行イメージ_未使用
private void SaveOcrResultWithAutoName(string currentTempPath, string detectedText)
{
try
{
// 保存先フォルダ(例:マイドキュメント内のScanOcrフォルダ)
string saveFolder = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments), "ScanOcr");
if (!Directory.Exists(saveFolder)) Directory.CreateDirectory(saveFolder);
// 新しいファイル名を生成
string newFileName = GenerateSafeFileName(detectedText);
string finalPath = Path.Combine(saveFolder, newFileName);
// 一時ファイルを正式な名前でコピー保存
File.Copy(currentTempPath, finalPath, true);
// ログやステータスバーに表示
// toolStripStatusLabel1.Text = $"保存完了: {newFileName}";
}
catch (Exception ex)
{
MessageBox.Show("ファイル名自動保存エラー: " + ex.Message);
}
}
//保存先指定
private void button5_Click(object sender, EventArgs e)
{
using (FolderBrowserDialog fbd = new FolderBrowserDialog())
{
fbd.Description = "スキャン画像の保存先フォルダを選択してください";
fbd.ShowNewFolderButton = true; // 新しいフォルダの作成を許可
if (fbd.ShowDialog() == DialogResult.OK)
{
selectedOcrFolder = fbd.SelectedPath;
// 選択したパスを画面のラベルやテキストボックスに表示しておくと親切です
lblFolderPath.Text = selectedOcrFolder;
}
}
}
//スキャンイメージ自動保存
private void AutoSaveScannedImage(string tempFilePath, string ocrResultText)
{
// 1. 保存先が選ばれていない場合はマイドキュメントをデフォルトにする
if (string.IsNullOrEmpty(selectedOcrFolder))
{
selectedOcrFolder = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments), "ScanOcr");
}
// フォルダが存在しない場合は作成
if (!Directory.Exists(selectedOcrFolder)) Directory.CreateDirectory(selectedOcrFolder);
try
{
// 2. OCRテキストから安全なファイル名を生成(前回のロジックを利用)
string newFileName = GenerateSafeFileName(ocrResultText);
string finalPath = Path.Combine(selectedOcrFolder, newFileName);
// 3. 一時ファイルを正式なパスへコピー(上書き許可)
File.Copy(tempFilePath, finalPath, true);
MessageBox.Show($"画像を保存しました:\n{newFileName}", "保存完了");
}
catch (Exception ex)
{
MessageBox.Show("保存に失敗しました: " + ex.Message);
}
}
//ADFスキャン
private void button6_Click(object sender, EventArgs e)
{
ScannerControl scanner = new ScannerControl();
// 保存先フォルダ(選択済み、またはデフォルト)
string saveDir = string.IsNullOrEmpty(selectedOcrFolder)
? Path.Combine(Application.StartupPath, "ScannedDocs")
: selectedOcrFolder;
if (!Directory.Exists(saveDir)) Directory.CreateDirectory(saveDir);
try
{
// 連続スキャンの実行(パスのリストが返ってくる)
// 引数の最後にカラーモード(カラーなら1、白黒なら4)を渡します
int mode = chkColor.Checked ? 1 : 4;
List<string> filePaths = scanner.StartScan(saveDir, true, chkA3Mode.Checked, mode);
if (filePaths.Count > 0)
{
//パス取得
actualFilePaths = filePaths; // ★ここでパスを「保存用リスト」に記憶させる
actualFilePath = filePaths[0];
currentPage = 0;
// 既存のコレクションをクリア、または新規作成
pdfImages?.Dispose();
pdfImages = new MagickImageCollection();
foreach (string path in filePaths)
{
// 各画像をコレクションに追加
pdfImages.Add(new MagickImage(path));
}
currentPage = 0;
DisplayCurrentPage(); // 1枚目を表示
MessageBox.Show($"{filePaths.Count}枚のスキャンが完了しました。\n「次へ」ボタンで内容を確認してOCRを実行してください。");
}
}
catch (Exception ex)
{
MessageBox.Show("連続スキャンエラー: " + ex.Message);
}
}
//Google OCR レスポンスからの座標抽出ロジック jsonより抽出
public List<OcrWordInfo> GetWordCoordinates(TextAnnotation annotation)
{
List<OcrWordInfo> wordList = new List<OcrWordInfo>();
if (annotation == null) return wordList;
foreach (var page in annotation.Pages)
{
foreach (var block in page.Blocks)
{
foreach (var paragraph in block.Paragraphs)
{
foreach (var word in paragraph.Words)
{
// 単語内の記号を連結して一つの文字列にする
string text = string.Join("", word.Symbols.Select(s => s.Text));
// 4隅の座標のうち、左上(index 0)を基準にする
var vertices = word.BoundingBox.Vertices;
// 安全策:頂点が4つ揃っていない場合はスキップ
if (vertices.Count < 4) continue;
wordList.Add(new OcrWordInfo
{
Text = text,
X = vertices[0].X,
Y = vertices[0].Y,
// 右上x - 左上x で幅を計算
Width = vertices[1].X - vertices[0].X,
// 左下y - 左上y で高さを計算
Height = vertices[3].Y - vertices[0].Y
});
}
}
}
}
return wordList;
}
public void CreateSearchablePdf(string imagePath, string outputPath, List<OcrWordInfo> words)
{
// iTextSharpのImageとして読み込み
iTextSharp.text.Image img = iTextSharp.text.Image.GetInstance(imagePath);
// ★重要:ここが scale の定義です
// スキャナー設定が 200dpi、PDFの標準が 72dpi なのでその比率を出します
float scale = 72f / 200f;
// 画像サイズ(ピクセル)にスケールを掛けて、PDF上のサイズ(ポイント)を算出
float pdfWidth = img.Width * scale;
float pdfHeight = img.Height * scale;
using (FileStream fs = new FileStream(outputPath, FileMode.Create))
{
// ページサイズを計算後のPDFサイズに合わせる
iTextSharp.text.Document doc = new iTextSharp.text.Document(new iTextSharp.text.Rectangle(pdfWidth, pdfHeight), 0, 0, 0, 0);
PdfWriter writer = PdfWriter.GetInstance(doc, fs);
doc.Open();
// 画像をPDFサイズにリサイズして配置
img.ScaleAbsolute(pdfWidth, pdfHeight);
img.SetAbsolutePosition(0, 0);
doc.Add(img);
PdfContentByte cb = writer.DirectContent;
// フォント指定(前回修正したMSゴシックのパス)
string fontPath = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.Fonts), "msgothic.ttc,0");
BaseFont bf = BaseFont.CreateFont(fontPath, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
cb.SetTextRenderingMode(PdfContentByte.TEXT_RENDER_MODE_INVISIBLE);
foreach (var word in words)
{
// ★ここで scale を使って文字サイズを計算
float fontSize = word.Height * scale;
// 「too small: 0」エラー対策
if (fontSize < 1.0f) continue;
cb.BeginText();
cb.SetFontAndSize(bf, fontSize);
// 座標計算(すべてに scale を掛ける)
float pdfX = word.X * scale;
float pdfY = pdfHeight - (word.Y * scale) - fontSize;
cb.ShowTextAligned(PdfContentByte.ALIGN_LEFT, word.Text, pdfX, pdfY, 0);
cb.EndText();
}
doc.Close();
}
}
//DB連携
private async void button7_Click(object sender, EventArgs e)
{
try
{
// 1. 登録データの準備
byte[] pdfData = File.ReadAllBytes(currentPdfPath); // 透過PDF本体
string ocrText = textBox1.Text; // OCR済みテキスト
string fileName = Path.GetFileName(currentPdfPath);
// 2. 接続文字列(環境に合わせて調整してください)
string connStr = "Server=localhost;Database=DocDB;MultipleActiveResultSets=true;";
connStr += ";User ID='sa';Password='ssk1009'";
using (SqlConnection conn = new SqlConnection(connStr))
{
await conn.OpenAsync();
// 3. インサート文の作成
string sql = @"INSERT INTO Documents (FileName, OcrText, PdfFile, CreatedDate,FileHash)
VALUES (@FileName, @OcrText, @PdfFile, GETDATE(),@hash)";
using (SqlCommand cmd = new SqlCommand(sql, conn))
{
// パラメータを介してバイナリを送る(SQLインジェクション対策と型安全のため)
cmd.Parameters.Add("@FileName", SqlDbType.NVarChar).Value = fileName;
cmd.Parameters.Add("@OcrText", SqlDbType.NVarChar).Value = ocrText;
cmd.Parameters.Add("@PdfFile", SqlDbType.VarBinary, -1).Value = pdfData; // -1はMAXを意味します
cmd.Parameters.AddWithValue("@hash", GetFileHash(pdfData)); // ここを追加!
await cmd.ExecuteNonQueryAsync();
}
}
MessageBox.Show("SQL Serverへの連携が完了しました!", "成功");
}
catch (Exception ex)
{
MessageBox.Show($"エラーが発生しました: {ex.Message}", "エラー");
}
}
// ファイルの「指紋」を作成するメソッド
public string GetFileHash(byte[] fileData)
{
using (SHA256 sha256 = SHA256.Create())
{
byte[] hashBytes = sha256.ComputeHash(fileData);
// バイト配列を16進数の文字列に変換
return BitConverter.ToString(hashBytes).Replace("-", "").ToLower();
}
}
}
}
は、 Gemini 2.5 ProやGoogle Cloud Vision API、Doc){kind=link}