Qt6 Python 画像より文字抽出 PYOCR OpenCV
事前作業
Pyocr
PyocrはGoogleが開発したOCRエンジンを使用してOCRを行うライブラリです。
インストール
pyocrと日本語のocrエンジンをダウンロードします。
pip install pyocr
apt install tesseract-ocr libtesseract-dev tesseract-ocr-jpn
下記のコマンドを実行してjpnと表示されたらインストール成功です。
!tesseract --list-langsOpenCVとは
OpenCVとは、画像処理・画像解析のために開発されたオープンソースのライブラリで、Python、C++など様々な言語で利用できます。
OpenCVを使うことでエッジや輪郭の抽出、物体検出などの画像処理をPythonで簡単に行えます。
OpenCVを利用する前にインストールする必要があります。
例えば、下記のようなコマンドでインストールしてから使ってみてください。
pip install opencv-pythonOpenCVでマウスクリックした場所の座標を取得する方法
それでは、OpenCVを使って画像の特定の場所の座標を取得する方法を説明します。
以下の2つの機能を順番に使います。
- OpenCVを使って画像を表示する
- OpenCVで表示した画像のクリックされた座標を取得する
Qt6Creatorでプロジェクト ImageToTextを作成
form.ui は、pyside6-uic form.ui -o ui_form.py を実行して ui_form.py を作成します。
form.ui
imagetotext.py
# This Python file uses the following encoding: utf-8
import sys
import os
from PySide6.QtWidgets import QApplication, QWidget,QFileDialog
from PIL import Image
import pyocr
import cv2
import numpy as np
# Important:
# You need to run the following command to generate the ui_form.py file
# pyside6-uic form.ui -o ui_form.py, or
# pyside2-uic form.ui -o ui_form.py
from ui_form import Ui_ImageToText
class ImageToText(QWidget):
def __init__(self, parent=None):
super().__init__(parent)
self.ui = Ui_ImageToText()
self.ui.setupUi(self)
self.ui.pushButton.clicked.connect(self.file_open)
self.ui.pushButton_2.clicked.connect(self.file_save)
self.ui.pushButton_3.clicked.connect(self.end)
self.ui.pushButton_4.clicked.connect(self.henkan)
self.ui.pushButton_5.clicked.connect(self.clear)
self.setStyleSheet("background-color:lightblue")
#cv2画像の倍率
self.ui.lineEdit_7.setText("0.15")
self.ui.lineEdit_8.setText("6")
self.ui.lineEdit_9.setText("jpn")
def file_open(self): #画像選択、OCR処理
# インストール済みのTesseractのパスを通す
path_tesseract = "C:\\Program Files\\Tesseract-OCR"
if path_tesseract not in os.environ["PATH"].split(os.pathsep):
os.environ["PATH"] += os.pathsep + path_tesseract
# 押したときの動作(ファイル選択ダイアログを開く)
self.fileName = QFileDialog.getOpenFileName(None,"ファイルを選択してください。")
#ファイル名が選択されていたらいろいろ表示
if self.fileName[0] != "":
#ファイル名をセット
self.ui.lineEdit.setText(self.fileName[0])
def onMouse(event, x, y, flags, params):
if event == cv2.EVENT_LBUTTONDOWN:
print(x, y)
xy = str(x) + "," + str(y) + ","
xyz = self.ui.lineEdit_2.text()
xy2 = xyz + xy
self.ui.lineEdit_2.setText(xy2)
pos = self.ui.lineEdit_2.text().split(',')
print(pos)
l=len(pos)
if l>4:
self.ui.lineEdit_3.setText(pos[l-5])
self.ui.lineEdit_4.setText(pos[l-4])
self.ui.lineEdit_5.setText(pos[l-3])
self.ui.lineEdit_6.setText(pos[l-2])
# Pillowで画像ファイルを開く日本語のファイル名のため
pil_img = Image.open(self.fileName[0])
# PillowからNumPyへ変換
img = np.array(pil_img)
# カラー画像のときは、RGBからBGRへ変換する
if img.ndim == 3:
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
#img = cv2.imread(self.fileName[0])
#倍率で表示する
ritu=float(self.ui.lineEdit_7.text())
img_fs=cv2.resize(img,None,fx=ritu,fy=ritu)
cv2.imshow('image', img_fs)
cv2.setMouseCallback('image', onMouse)
cv2.waitKey(0)
def henkan(self): #画像選択、OCR処理
tools = pyocr.get_available_tools()
assert(len(tools) != 0)
tool = tools[0]
#対応言語取得
langs = tool.get_available_languages()
print("対応言語:",langs) # ['eng', 'jpn', 'osd']
# 原稿画像の読み込み
img_org = Image.open(self.fileName[0])
img_box = Image.open(self.fileName[0])
pos = self.ui.lineEdit_2.text().split(',')
l=len(pos)
if l>4:
# 番号の部分を切り抜き
ritu=float(self.ui.lineEdit_7.text())
x1=int(self.ui.lineEdit_3.text())/ritu
y1=int(self.ui.lineEdit_4.text())/ritu
x2=int(self.ui.lineEdit_5.text())/ritu
y2=int(self.ui.lineEdit_6.text())/ritu
img_box = img_org.crop((x1, y1, x2, y2))
opt = int(self.ui.lineEdit_8.text())
gen = self.ui.lineEdit_9.text()
text = tool.image_to_string(
img_box,
lang=gen,
builder=pyocr.builders.TextBuilder(tesseract_layout=opt) # ここが重要
)
self.ui.textEdit.setText(text)
def file_save(self): #ファイル保存
options = QFileDialog.Options()
options |= QFileDialog.DontUseNativeDialog
fileName , _ = QFileDialog.getSaveFileName(self,"Save File", "", "All Files(*);;Text Files(*.txt)", options = options)
if fileName:
with open(fileName, 'w') as f:
f.write(self.ui.textEdit.toPlainText())
def clear(self):
self.ui.lineEdit_2.setText("")
self.ui.lineEdit_3.setText("")
self.ui.lineEdit_4.setText("")
self.ui.lineEdit_5.setText("")
self.ui.lineEdit_6.setText("")
def end(self):
self.close()
if __name__ == "__main__":
app = QApplication(sys.argv)
widget = ImageToText()
widget.show()
sys.exit(app.exec())
実行画面
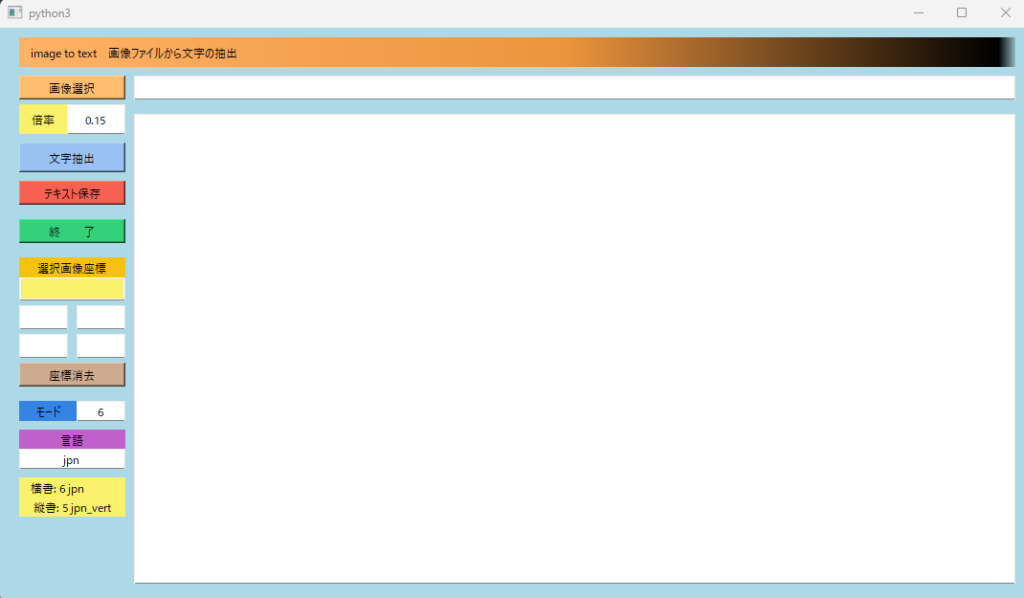
画面選択ボタンを押下して画像ファイルを選択します。画像が表示されます。倍率で表示サイズを変更できます。規定は、0.15倍です。
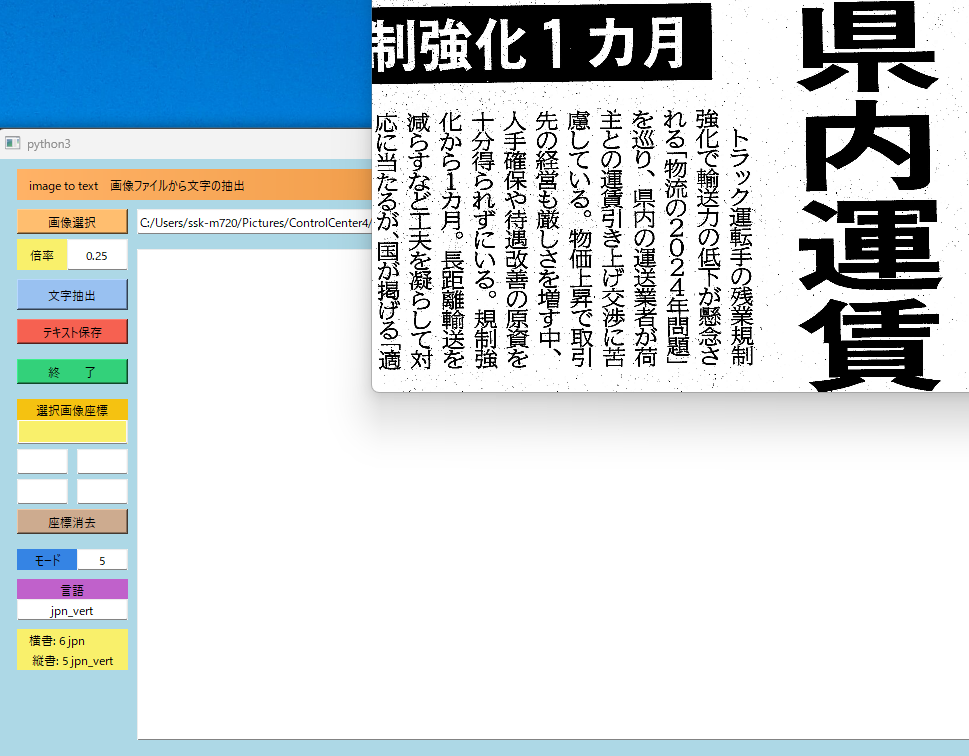
抽出したい領域をマウスで始点と終点を指定します。選択画像座標に値が設定されます。文字抽出ボタンを押下。内容が表示されます。テキスト保存ボタンでファイル保存できます。選択座標なしの場合は、全体が対象となります。
ページセグメンテーションモードについて
特定の画像に特化したレイアウト解析をするためのオプションを指定する。このオプションを指定した場合、画像の種類によっては文字認識の結果が改善される可能性がある。
| オプション | 説明 |
|---|---|
| 0 | 文字角度の識別と書字系のみの認識(OSD)のみ実施(outputbase.osdが出力され、OCRは行われない) |
| 1 | OSDと自動ページセグメンテーション |
| 2 | OSDなしの自動セグメンテーション(OCRは行われない) |
| 3 | OSDなしの完全自動セグメンテーション(デフォルト) |
| 4 | 可変サイズの1列テキストを想定する |
| 5 | 縦書きの単一のテキストブロックとみなす |
| 6 | 単一のテキストブロックとみなす(5と異なる点は横書きのみ) |
| 7 | 画像を1行のテキストとみなす |
| 8 | 画像を単語とみなす |
| 9 | 円の中に記載された1単語とみなす(例:①、⑥など) |
| 10 | 画像を1文字とみなす |
| 11 | まだらなテキスト。特定の順序でなるべく多くの単語を検出する(角度無し) |
| 12 | 文字角度検出を実施(OSD)しかつ、まだらなテキストとしてなるべく多くの単語を検出する |
| 13 | Tesseract固有の処理を回避して1行のテキストとみなす |
Tesseractのダウンロード
LinuxやMacではレポジトリからインストールできますが、Windowsについてはドイツのマンハイム大学図書館提供のインストーラーを利用できます。マンハイム大学図書館はTesseractで歴史的な新聞の文字認識を行っています。
Home · UB-Mannheim/tesseract Wiki · GitHubのページにアクセスしてWindows用のインストーラーをダウンロードします。32bit版と64bit版があります
{kind=link}